How to accurately predict stock market prices. Great qualitative investors such as Warren Buffet have conceded that they cannot predict the market, and also quantitative firms using people with PhDs have tried to use technology to predict that market and have failed. Big banks such as Goldman Sachs or J.P. Morgan have spent millions of dollars buying algorithms and hiring people to get closer and closer to solving this problem. The main issue with predicting stock prices is that no one can predict the future. That’s why machine learning has burst onto the scene because the goal of machine learning is to predict future values. The complication with the stock market comes because much of what affects stock market prices has nothing to do with data or anything quantitative. Stock market prices are driven by the emotion of investors. It is possible to use as much data as possible to predict how airline stock prices will move, but if the President has a press conference and bans travel by airplanes it is nearly impossible for a computer to predict events like that. I plan to use real-time stock data from numerous python libraries along with the content we have learned in this glass to create a neural network to predict stock prices.
To predict pictures of cats and dogs first we created different directories for training and validation and then within those directories we created subdirectories for cat pictures and dog pictures. We then split the 90% of the data into picture for testing and the rest for validation. We imported the optimizer RMSprop and set the learning rate to 0.001.
We used the binary_crossentropy loss function. The loss function is penalizing bad predictions by taking the probability of the of the the prediction and is taking the negative log value of it. If the probability of selecting a value is 1 the log of 1 is equal to 0 which effectively means no loss because the value is guaranteed to be correct, but if the probability is .25 it is calculated as -log(0.25) = 0.602
The metric argument is supposed to judge your model. The one we used in the program was ‘acc’. ‘acc’ just calculates how many times the program correctly matched the predicted label to the actual label.
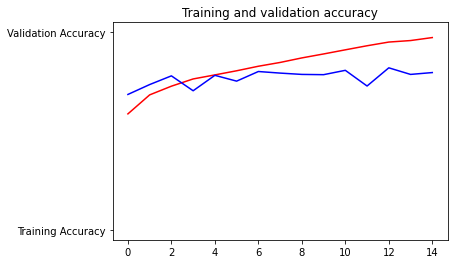
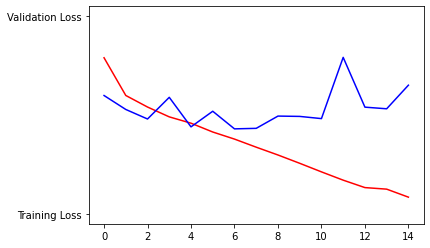
The model did a good job at predicting cats and dogs, but it was a bit overfit.
The model said each of the images below were dogs





