One-hot encoding can be inefficient because it cannot take into account the meaning of words. Word embedding takes into account the meaning of words and assigns weights to each word.
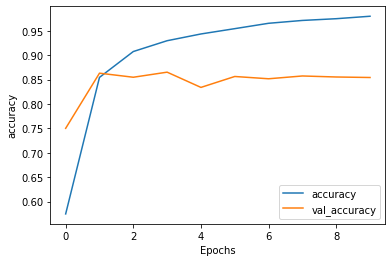
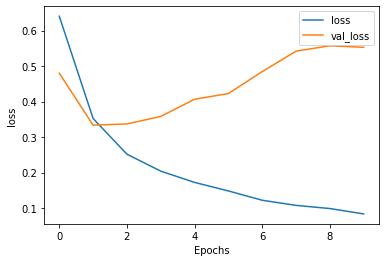
Although the model does a pretty good job of predicting, it is overfit. This can be seen by the gap between the training accuracy and validation accuracy and also in the loss graph the validation loss starts to grow much faster while the training loss keeps decreasing.
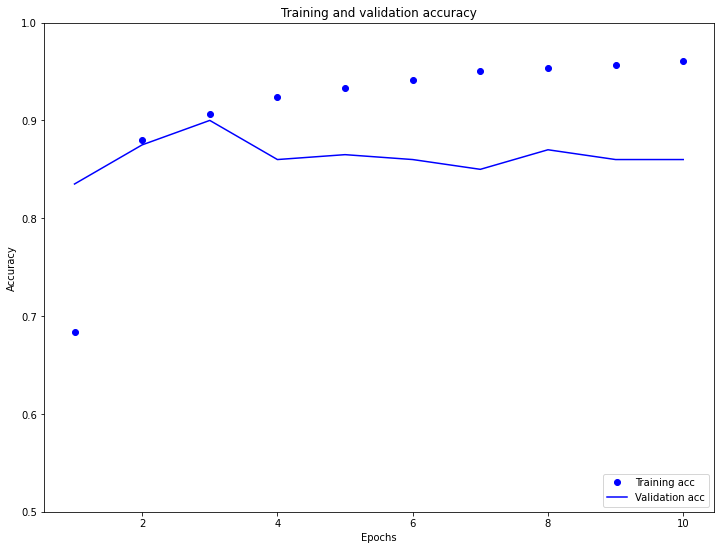
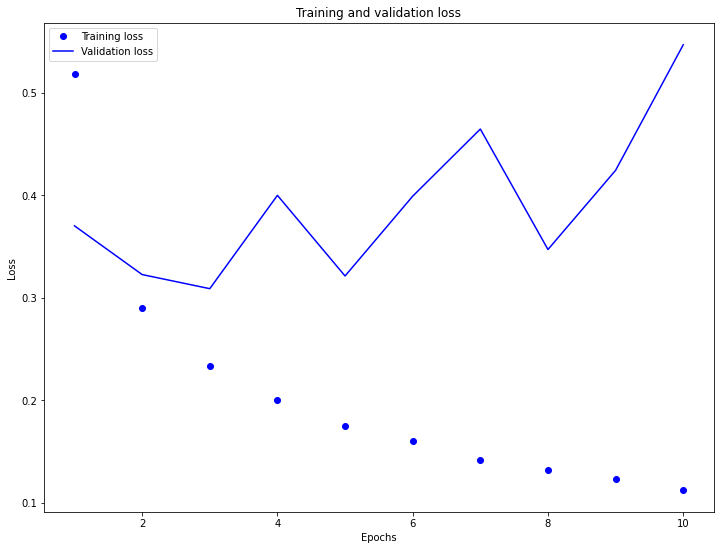
The results are pretty much similar to the graphs above. The model is overfit.
Without LTSM:
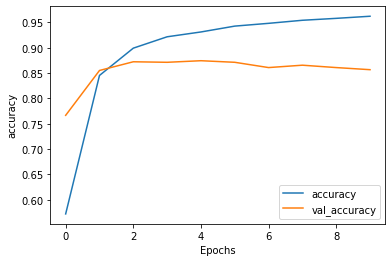
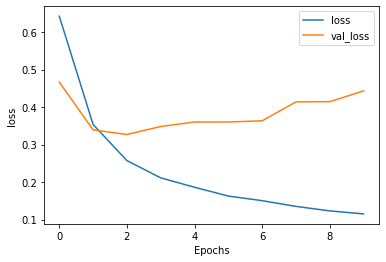
With LTSM: