The reason why the groups were split was because to train the network the program had to practice on a set of data in order to be able to take in new information. So the model split it into groups of training and testing data ad it practiced using the training data and then it used the testing data to gauge how accurate it is.
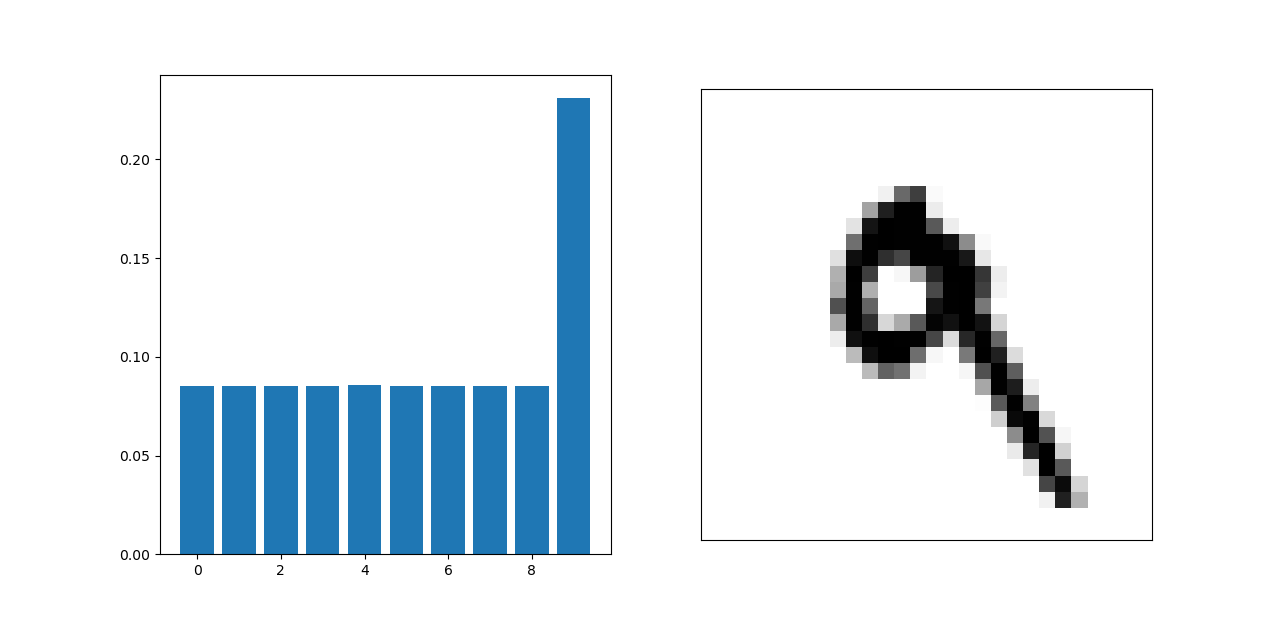
The RELU function is supposed to set outputs less than 0 to 0 so it doesn’t skew the outputs. Softmax helps find the most likely answer by setting the highest probability equal to one. There are 10 layers because there are 10 different options that the output could be.
The loss function calculates how far off the predicted value was to the actual value. The optimizer then updates and changes how to minimize the loss and then feeds it back to the loss function and repeats over and over again until it is at the minimum loss.
(60000, 28, 28)
60000
(10000, 28, 28)